Press release
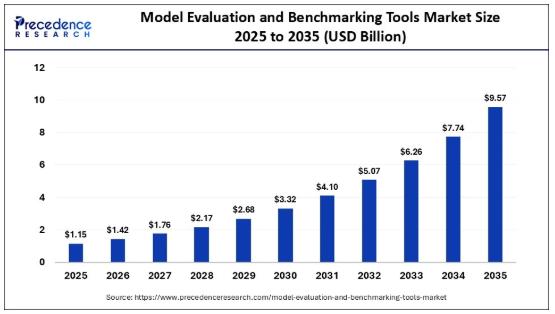
Model Evaluation and Benchmarking Tools Market Size Expected to Reach USD 9.57 Billion by 2035
As artificial intelligence (AI) technologies become more integral to business operations, the demand for reliable and scalable model evaluation and benchmarking tools has surged. These tools play a crucial role in assessing AI models' accuracy, performance, bias, and robustness, ensuring that businesses can deploy models with confidence in real-world environments. The growing complexity of AI models, coupled with the expansion of enterprise AI ecosystems, is propelling market growth, with AI adoption accelerating across industries.
Where Data Meets Strategic Clarity 📥 View Sample Pages of the Complete Report 👉 https://www.precedenceresearch.com/sample/8326
AI's Role in Market Growth
Artificial intelligence is both a key driver and a catalyst in transforming the model evaluation and benchmarking tools market. AI's rising integration into enterprise AI systems, such as large language models (LLMs) and multimodal models, necessitates advanced evaluation techniques that go beyond traditional benchmarks.
The role of AI in enhancing the standardization of evaluation processes is significant automating benchmarking pipelines and enabling real-time validation are just a few ways AI is helping businesses stay competitive. These tools ensure that AI models are trustworthy, transparent, and compliant with emerging regulatory standards.
Moreover, AI has enabled the growth of new tools designed to measure interpretability, accountability, and bias. As businesses continue to face scrutiny regarding AI ethics, transparent evaluation and continuous monitoring of AI systems have become essential components of modern AI governance.
🔗 What's Fueling the Next Wave of Growth? 👉 https://www.precedenceresearch.com/model-evaluation-and-benchmarking-tools-market
Model Evaluation and Benchmarking Tools Market Key Growth Factors
🔹 Increased Complexity of AI Models: As AI systems grow more sophisticated, the need for robust evaluation tools increases. These tools ensure that AI models meet the high standards required in critical applications such as healthcare, finance, and autonomous systems.
🔹 MLOps Integration: The adoption of MLOps (machine learning operations) frameworks in enterprise AI systems is driving the need for automated benchmarking systems that integrate seamlessly within the AI lifecycle.
🔹 Regulatory Compliance and AI Governance: The increasing focus on responsible AI practices, particularly in sectors like healthcare and finance, is driving the demand for tools that ensure AI models adhere to regulatory standards.
➡️ Become a valued research partner with us https://www.precedenceresearch.com/schedule-meeting
Opportunities and Trends in the Model Evaluation and Benchmarking Tools Market
🔹 Shift to Dynamic, Real-World Testing: Static benchmarks are becoming less effective as AI models surpass conventional tests. More businesses are embracing dynamic, scenario-based testing to simulate real-world environments, enhancing the accuracy and applicability of AI evaluations.
🔹 AI Explainability and Transparency: There is a growing need for tools that provide explainability in AI models, particularly in sectors with high ethical and regulatory standards. Tools focused on measuring interpretability and fairness are gaining traction.
🔹 AI is playing a pivotal role in automating the benchmarking process, reducing manual effort, and ensuring that evaluation systems can scale with the complexity of modern AI models. This trend is expected to continue, as more companies integrate AI-driven evaluation tools into their workflows.
🔓 Instant Access. Zero Waiting. 📥 Buy the Premium Market Research Report Now 👉 https://www.precedenceresearch.com/checkout/8326
Model Evaluation and Benchmarking Tools Market Size and Forecasts
• Market size in 2025: USD 1.15 Billion
• Market size in 2026: USD 1.42 Billion
• Market size by 2035: USD 9.57 Billion
• CAGR: 9.57% (2026-2035)
• Forecast period: 2026-2035
• Base year: 2025
Model Evaluation and Benchmarking Tools Market Regional Analysis
North America led the market with a 42% share in 2025, driven by advanced AI ecosystems, strong enterprise adoption, and a focus on responsible AI and governance frameworks. The U.S. dominates the regional market due to widespread AI deployment across industries such as cloud computing, defense, and enterprise software, along with strong integration of evaluation tools in MLOps pipelines.
Europe held a 25% share in 2025 and is expected to grow at a CAGR of 21.5%. Growth is driven by strict regulations and data protection frameworks like GDPR, encouraging governance-focused AI evaluation. Germany plays a key role in Europe, with strong adoption in manufacturing and automotive sectors, emphasizing compliance, transparency, and reliability in AI systems.
Asia Pacific is the fastest-growing region with a CAGR of 27.5% and a 25% share in 2025. Growth is fueled by large-scale investments in AI innovation and digital transformation. China's market is driven by extensive AI adoption in e-commerce, finance, and infrastructure, with a strong focus on scalable, high-performance benchmarking tools.
Note: This report is readily available for immediate delivery. We can review it with you in a meeting to ensure data reliability and quality for decision-making.
Try Before You Buy - Get the Sample Report@ https://www.precedenceresearch.com/sample/8326
Model Evaluation and Benchmarking Tools Market Segment Analysis
🔹 Tool Type Insights
Model Validation & Testing Platforms: This segment led the market with a 28% share in 2025, driven by the growing need for structured validation pipelines that ensure AI model accuracy, reliability, and production readiness. Organizations rely on these platforms to detect failures and test model robustness before deployment.
Performance Monitoring & Drift Detection Tools: Holding a 22% share in 2025, this segment is expected to grow at a strong CAGR of 23%. Growth is fueled by the need to maintain model reliability post-deployment through real-time monitoring and detection of data or concept drift.
Benchmarking Frameworks: With an 18% share in 2025, benchmarking frameworks are projected to grow at a CAGR of 22%. They help organizations compare model performance using standardized datasets, measuring accuracy, latency, and efficiency.
Explainability & Interpretability Tools (XAI): Accounting for 15% of the market in 2025, this segment is growing at a CAGR of 21.5%. Rising regulatory and ethical demands are driving adoption, as these tools enhance transparency and trust in AI systems.
Bias, Fairness & Risk Evaluation Tools: This segment held a 17% share in 2025 and is expected to grow at the highest CAGR of 26.5%. Increasing regulatory scrutiny and the need to mitigate operational and reputational risks are key growth drivers.
🔹 Deployment Type Insights
Cloud-Based Evaluation Platforms: Dominating with a 65% share in 2025, cloud-based platforms are widely adopted due to their scalability and seamless integration with MLOps pipelines, enabling efficient testing and monitoring of large-scale AI models.
On-Premise Model Testing Tools: This segment accounted for 20% of the market in 2025 and is projected to grow at a CAGR of 14.5%. Demand is driven by organizations requiring strict data privacy, control, and enhanced governance.
Hybrid Evaluation Environments: Holding a 15% share in 2025, hybrid solutions are expected to grow at a CAGR of 23%. They combine cloud scalability with on-premise control, offering flexibility, compliance, and performance optimization.
🔹 Model Type Insights
Large Language Models (LLMs): LLMs dominated the market with a 35% share in 2025 due to the rapid adoption of generative AI. Increasing demand for evaluating reasoning accuracy and minimizing hallucinations is boosting this segment.
Predictive & Classical ML Models: With a 25% share in 2025, this segment is growing at a CAGR of 19.5%. These models remain essential in enterprise applications such as fraud detection, demand forecasting, and recommendation systems.
Speech & Multimodal Models: This segment held a 20% share in 2025 and is projected to grow at a CAGR of 25%. Growth is driven by rising adoption of AI systems that process text, audio, and visual data simultaneously.
🔹 Application Insights
AI Model Validation & QA: Leading with a 30% share in 2025, this segment is driven by the need for rigorous pre-deployment testing to ensure reliable AI outputs and minimize operational risks.
Regulatory Compliance & AI Governance: With a 20% share in 2025, this segment is expected to grow at the highest CAGR of 26.5%. Increasing regulatory pressure is driving demand for transparency, fairness, and accountability in AI systems.
Model Performance Optimization: Also holding a 20% share, this segment is projected to grow at a CAGR of 22%. Organizations use these tools to improve efficiency, reduce latency, and enhance model performance.
Benchmarking for Model Selection & Procurement: This segment accounted for 10% of the market in 2025 and is expected to grow at a CAGR of 21%, as enterprises increasingly rely on benchmarking to select optimal AI models.
🔹 End-Use Industry Insights
IT & Telecommunications: This segment dominated the market with a 30% share in 2025 due to large-scale AI deployment and increasing demand for reliable network performance amid growing data traffic and 5G expansion.
BFSI (Banking, Financial Services, and Insurance): Holding 15% share, BFSI is growing at a CAGR of 22%, driven by AI use in fraud detection, credit scoring, and risk management.
Healthcare: Also accounting for 15%, this segment is projected to grow at a CAGR of 24.5%, fueled by AI applications in medical imaging, patient monitoring, and diagnostics.
Retail & E-commerce: With a 15% share, this segment is growing at a CAGR of 23.5%, supported by digital transformation and the need for real-time, data-driven decision-making.
Automotive & Mobility: This segment held a 25% share in 2025 and is expected to grow at the highest CAGR of 25.5%, driven by the complexity of autonomous systems and the need for robust validation frameworks.
Government & Defense: Holding a 35% share, this segment is projected to grow at a CAGR of 24%, supported by increasing AI adoption in surveillance, intelligence, and compliance.
Model Evaluation and Benchmarking Tools Market Top Companies and Their Offerings
➢ Amazon Web Services (AWS)
↳ FMBench (Foundation Model Benchmarking Tool): Python‐based tool to benchmark foundation models (FMs) on Amazon SageMaker, Amazon Bedrock, Amazon EC2, and Amazon EKS for performance and accuracy; supports bring‐your‐own‐endpoint mode and "panel of LLM evaluators"‐driven assessments.
↳ Bedrock + SageMaker integrations: Customers can evaluate and compare third‐party and custom FMs on AWS by running standardized benchmarks, latency testing, and cost‐aware performance profiling.
➢ ClearML Ltd.
↳ ClearML experiment comparison UI: Provides built‐in model‐comparison views (scalars, plots, debug samples, configuration diffs) so data scientists can visually compare multiple model runs, hyperparameters, and metrics on the same problem.
↳ Experiment‐tracking‐enabled evaluation: Tracks metrics, artifacts, and logs across training and evaluation runs, enabling structured A/B testing of model variants and automated drift/incident detection via integrations.
➢ Databricks, Inc.
↳ Model evaluation in Databricks Notebooks & Workflows: Enables offline evaluation of LLMs and classical ML models using custom metrics, prompt‐based scoring, and RAG‐specific evaluation patterns over managed data lakes.
↳ Databricks AI Playground / GenAI evaluation: Offers centralized playgrounds to compare multiple LLMs and configurations on prompts, metrics, and evaluation rubrics; supports RAG‐system tuning and cost‐optimized evaluation at scale.
➢ DataRobot, Inc.
↳ Automated and statistical evaluation tools: Provides built‐in statistical evaluation, CI/CD‐style testing, and A/B testing for generative AI experiments, with head‐to‐head model comparison to select the best‐performing configuration.
↳ LLM‐focused evaluation metrics: Playground‐style interface to benchmark LLMs on different prompts, chunking, embeddings, and RAG configurations, with standardized metrics to rank candidate models.
➢ Domino Data Lab, Inc.
↳ Enterprise AI Platform model evaluation: Tracks model‐quality degradation, data drift, and accuracy metrics in production; integrates with monitoring and alerting to trigger retraining when performance drops.
↳ LLM evaluation frameworks & offline experiments: Supports LLM evaluation workflows, including custom scoring, offline evaluation mechanisms, and integration with popular evaluation libraries (e.g., Evidently, MLflow).
➢ Google LLC (Alphabet Inc.)
↳ Vertex AI Evaluation Service (LLM Comparator): GenAI evaluation service that lets customers benchmark any generative model (Google and third‐party) using custom and pre‐built metrics; supports pairwise comparisons, judge‐model scoring, and drift‐aware evaluation.
↳ LMEval (Large‐Model Evaluator): Open‐source framework for cross‐provider LLM benchmarking on standardized datasets and tasks, aimed at simplifying cross‐model evaluation across cloud providers.
➢ Hugging Face, Inc.
↳ Evaluate library: Open‐source Python library that provides ready‐to‐use metrics (accuracy, precision, recall, etc.) for many ML tasks and supports benchmarking and comparison of multiple models on the same dataset.
↳ YourBench / HF‐bench ecosystem: Tools and configurations to benchmark large language models on customer‐specific data (e.g., RAG, QA, reasoning), with reusable pipelines and evaluation datasets hosted on the Hub.
➢ IBM Corporation
↳ Foundation Model Evaluation (FM‐eval) framework: Systematic framework in watsonx.ai to evaluate and validate new LLMs using predefined benchmarks for quality, safety, and performance; leverages IBM‐developed Unitxt and LM Evaluation Harness‐based tooling.
↳ Model benchmarks in watsonx.ai: Built‐in leaderboards and benchmark tabs for comparing foundation models on scores from 0-100 across multiple benchmark types; supports customer‐owned‐data evaluations.
➢ Microsoft Corporation
↳ Azure AI Foundry / Microsoft Foundry model benchmarks: Model catalog with leaderboards and benchmark dashboards for language and embedding models, including quality, safety, cost, latency, and throughput metrics.
↳ Evaluation tools for multimodal apps: Integrates evaluators (often powered by multimodal LLMs) to grade generated content and run benchmarking pipelines as part of CI/CD for Azure AI apps.
➢ MLCommons Association
↳ MLCommons benchmarks (MLPerf‐style): Publishes standardized, community‐driven benchmarks (e.g., inference, training, and now foundation‐model suites) for fair, reproducible performance comparisons across vendors and hardware.
↳ MLHarness / unit‐testing‐style tooling: Provides scalable benchmarking systems that plug into MLCommons benchmarks and support end‐to‐end evaluation of model quality and performance in enterprise settings.
➢ OpenAI, Inc.
↳ OpenAI Evals framework: Infrastructure and API for defining and running evaluation suites over OpenAI models (e.g., GPT‐4, GPT‐3.5); users specify evaluation criteria, datasets, and scoring logic, then run and analyze eval runs asynchronously.
↳ Dashboard and API‐driven evaluation: Evaluation runs are exposed via a dashboard and webhook‐enabled API, enabling programmatic scoring of outputs and continuous evaluation in CI/CD pipelines.
➢ SAS Institute Inc.
↳ SAS‐Bench and domain‐specific evaluation suites: Introduces fine‐grained benchmarks such as SAS‐Bench for short‐answer‐style reasoning and exam‐style questions, providing step‐wise scoring and error categorization for LLM‐based reasoning systems.
↳ Model and analytics evaluation: Enterprise analytics platform includes statistical‐model‐evaluation capabilities and benchmarking for classical ML and optimization models, often integrated into broader governance workflows.
➢ Scale AI, Inc.
↳ Scale Evaluation platform: New "Scale Evaluation" product that automates model testing across multiple benchmarks, surface model weaknesses, and recommends targeted training‐data improvements.
↳ Benchmark automation and feedback loops: Designed to streamline evaluation of vision, NLP, and multimodal models at scale, integrating with human‐labeling workflows on the Scale platform.
➢ Snowflake Inc.
↳ Cortex‐enabled model evaluation: In Snowflake Cortex, customers can evaluate Text‐to‐SQL, BI‐assistant, and analytics‐focused models using internal evaluation setups that generate candidate SQL outputs, compare against human‐curated "gold" SQL, and score on column‐based precision/recall rather than exact string match.
↳ Cross‐model benchmarking in data lake environment: Leverages Snowflake's unified data architecture to run comparative evaluations over real‐world BI and analytics workloads, tuned for SQL generation and analytics accuracy.
➢ Weights & Biases, Inc. (W&B)
↳ W&B Weave / GenAI evaluation tools: Provides GenAI‐focused evaluation tooling (e.g., Weave) for running LLM evaluations, benchmarking experiments, and visualizing results in dashboards; supports declarative evaluation specs and continuous testing pipelines.
↳ Experiment‐tracking‐based benchmarking: Tracks model runs, predictions, and metrics over time, enabling comparison of multiple LLMs, prompts, and pipelines in a unified workspace for robust model‐selection workflows.
Latest Industry Updates
⚡ In April 2026, Endor Labs launched a new agentic code security benchmark, extending the SusVibes framework to evaluate AI-generated code security, reinforcing the need for robust security measures in AI models.
⚡ In April 2026, Rapid Evaluation Framework (REF) was introduced to enhance climate model evaluations, setting a new standard in environmental AI applications.
Thank you for reading. You can also get individual chapter-wise sections or region-wise report versions, such as North America, Europe, or Asia Pacific.
📥 Instant Report Delivery Available | 💳 Buy Now 👉 https://www.precedenceresearch.com/checkout/8326
Segments Covered in the Report
🔸 By Tool Type
Model Validation & Testing Platforms
Benchmarking Frameworks (LLM Benchmarks, Vision Benchmarks)
Explainability & Interpretability Tools (XAI)
Bias, Fairness & Risk Evaluation Tools
Performance Monitoring & Drift Detection Tools
🔸 By Deployment Mode
Cloud-based Evaluation Platforms
On-premise Model Testing Tools
Hybrid Evaluation Environments
🔸 By Model Type
Large Language Models (LLMs)
Computer Vision Models
Speech & Multimodal Models
Predictive & Classical ML Models
🔸 By Application
AI Model Validation & QA
Regulatory Compliance & AI Governance
Model Performance Optimization
Continuous Monitoring & MLOps Integration
Benchmarking for Model Selection & Procurement
🔸 By End-Use Industry
IT & Telecommunications
BFSI
Healthcare
Retail & E-commerce
Automotive & Mobility
Government & Defense
Others
🔸 By Region
North America
Latin America
Europe
Asia-pacific
Middle and East Africa
Connect With Us
📞 USA: +1 804 441 9344
📞 APAC: +61 485 981 310 or +91 87933 22019 | +6531051271
📞 Europe: +44 7383 092 044
📩 Email: sales@precedenceresearch.com
Precedence Research is a worldwide market research and consulting organization. We give an unmatched nature of offering to our customers present all around the globe across industry verticals. Precedence Research has expertise in giving deep-dive market insight along with market intelligence to our customers spread crosswise over various undertakings. We are obliged to serve our different client base present over the enterprises of medicinal services, healthcare, innovation, next-gen technologies, semi-conductors, chemicals, automotive, and aerospace & defense, among different ventures present globally.
🌐 Web: https://www.precedenceresearch.com
Our Trusted Data Partners:
🔹https://www.towardshealthcare.com
🔹https://www.towardspackaging.com
🔹https://www.towardschemandmaterials.com
🔹https://www.towardsfnb.com
🔹https://www.marketstatsinsight.com
Get Recent News:
https://www.precedenceresearch.com/news
For the Latest Update, Follow Us:
🔹https://www.linkedin.com/company/precedence-research
🔹https://x.com/Precedence_R
🔹https://www.facebook.com/precedenceresearch
🔹https://precedence-research.medium.com/
This release was published on openPR.
Permanent link to this press release:
Copy
Please set a link in the press area of your homepage to this press release on openPR. openPR disclaims liability for any content contained in this release.
You can edit or delete your press release Model Evaluation and Benchmarking Tools Market Size Expected to Reach USD 9.57 Billion by 2035 here
News-ID: 4483868 • Views: …
More Releases from Precedence Research
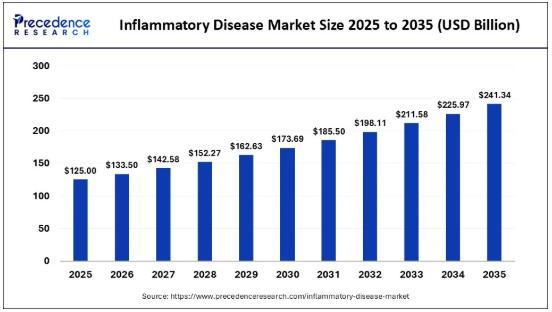
Inflammatory Disease Market Size to Surge to USD 241.34 Billion by 2035
According to Precedence Research, the global inflammatory disease market size was valued at USD 125.00 billion in 2025 and is projected to surge to USD 241.34 billion by 2035, expanding at a CAGR of 6.80% from 2026 to 2035. This surge is driven by an increasing prevalence of chronic inflammatory disorders, growing demand for targeted therapies, and advancements in biologics and diagnostics. As the market continues to evolve, innovative treatments…
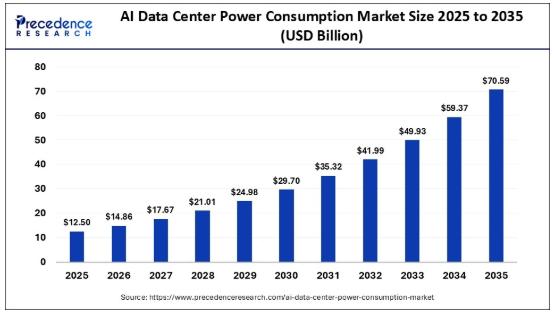
AI Data Center Power Consumption Market Size to Surge from USD 12.50 Billion in …
According to Precedence Research, the global AI data center power consumption market size is projected to expand from USD 12.50 billion in 2025 to approximately USD 70.59 billion by 2035, reflecting a robust CAGR of 18.90% from 2026 to 2035. This meteoric rise is attributed to the increasing demands placed on data centers by AI workloads, including generative AI, machine learning, and deep learning. With the proliferation of AI-driven applications…
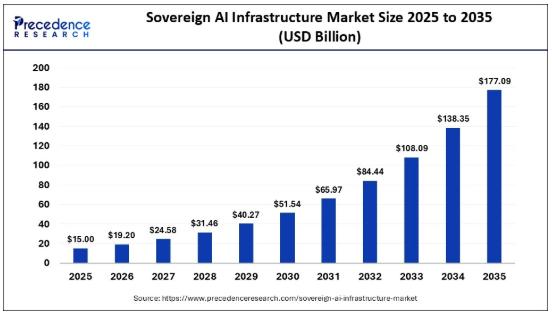
Sovereign AI Infrastructure Market Size Projected to Reach USD 177.09 Billion by …
According to Precedence Research, the global sovereign AI infrastructure market size will grow from USD 15.00 billion in 2025 to nearly USD 177.09 billion by 2035, expanding at a robust CAGR of 28.00% from 2026 to 2035. This market expansion is driven by the urgency for national security through AI sovereignty, data control to mitigate geopolitical risks, and the race to maintain competitiveness in AI development.
Sovereign AI infrastructure refers…
Cholestatic Pruritus Market Size Forecasted to Reach USD 2.55 Billion by 2035
According to Precedence Research, the global cholestatic pruritus market size will grow from USD 1.40 billion in 2025 to nearly USD 2.55 billion by 2035, expanding at a CAGR of 6.20% from 2026 to 2035. This growth is fueled by an increased focus on novel therapeutic options, enhanced diagnostic tools, and a rise in healthcare awareness.
AI's Role in the Cholestatic Pruritus Market
Artificial intelligence (AI) is increasingly playing a crucial role…
More Releases for Mode
Electrical Common Mode Chokes Market
Electrical Common Mode Chokes Market Overview
Electrical common mode chokes consist of two or more coils of insulated wire on a single magnetic core. Each winding is put in series with one of the conductors. This means that the magnetic fields of the wires combine to present high impedance to the noise signal.
This report provides a deep insight into the global Electrical Common Mode Chokes market covering all its essential aspects.…
Dog Barking Device Market 2024 Product Types ( Sound Mode, Vibration Mode, and …
The "Dog Barking Device Market" report provides key insights into market size, share, growth dynamics, and emerging trends, enabling businesses to make data-driven decisions and enhance their strategies for expansion. It also highlights technological advancements, diverse sales channels, market penetration, production methods, and company revenues, offering a holistic perspective of the market landscape.
Browse Full Report at: https://www.themarketintelligence.com/market-reports/dog-barking-device-market-1640
About Dog Barking Device Market:
The global dog barking device market size was USD 805.9 million…
MCHOSEUnveilsNewG3SeriesWirelessTri-Mode Gaming Mouse
MCHOSE has announced its latest wireless tri-mode connectivity gaming mice-the MCHOSE G3 series. This series includes four models: G3 SE, G3, G3 Pr, and G3 Ultra. The entry-level models, G3 SE and G3 come with the PixArt PAW3311 sensor and support 1K wired and wireless polling rates. Higher-end models feature the PAW3395 sensor, offering 8K polling rates and extremely low average latency, delivering an unprecedented gaming experience to players.
Image: https://www.getnews.info/uploads/d77a391503704cc867e081fe5079b670.png
Performance…
Switch Mode Power Supply Transformers Market
The Business Research Company's global market reports are now updated with the latest market sizing information for the year 2023 and forecasted to 2032
Switch Mode Power Supply Transformers Market Size, Growth Rate, And Forecast
The global switch mode power supply transformers market size grew from $1.58 billion in 2022 to $1.5 billion in 2023 at a compound annual growth rate (CAGR) of -4.8%. The Russia-Ukraine war disrupted the chances of…
Global Mixed Mode Chromatography Resin Market
According to a new market research report published by Global Market Estimates, the Global Mixed Mode Chromatography Resin Market is projected to grow at a CAGR of 7.8% from 2023 to 2028.
GE Healthcare Life Sciences, JSR Micro Inc., Kaneka Corporation, Knauer Gmbh, Life Technology Corporation, Merck, Pall Corporation, Purolite Corporation, Sepragen Corporation, and Thermo Fisher Scientific among others are some of the key players in the global mixed mode chromatography…
Experiencing awnings in AR mode
The Augmented Reality App from markilux is now even more user-friendly
markilux has brought its app up to date. On the one hand, this provides even better sales support for the awning specialist’s partners. On the other, it makes it very easy for an end consumer to select an awning for their own home in advance, as this tool allows awning models not only to be configured as desired, but also…
