Press release
AI Training Dataset Market Futuristic Opportunity, High CAGR Value, Emerging Demands and Future Outlook

Scale AI (US), Appen (Australia), AWS (US), TELUS International (Canada), Sama (US), Snorkel AI (US), V7 Labs (UK), Alegion (US), Toloka AI (US).
The AI Training Dataset Market [https://www.marketsandmarkets.com/Market-Reports/ai-training-dataset-market-153819655.html?utm_source=abnewswire.com&utm_medium=referral&utm_campaign=ai-training-dataset-market] is expected to increase from an anticipated USD 2.82 billion in 2024 to USD 9.58 billion by 2029, growing at a compound annual growth rate (CAGR) of 27.7% throughout the forecast period. This expansion is mostly driven by the growing need for high-quality AI datasets to support machine learning (ML) data generation and AI model training. The need for a variety of labeled datasets has increased due to the rapid adoption of AI in sectors like healthcare, finance, autonomous systems, and natural language processing (NLP). To improve model performance, organizations are making significant investments in data labeling, synthetic data synthesis, and LLM datasets. Companies are using automation, crowdsourcing, and AI-powered annotation technologies to effectively select and organize specialized datasets.
Download PDF Brochure@ https://www.marketsandmarkets.com/pdfdownloadNew.asp?id=153819655 [https://www.marketsandmarkets.com/pdfdownloadNew.asp?id=153819655&utm_source=abnewswire.com&utm_medium=referral&utm_campaign=ai-training-dataset-market]
The market for AI training datasets has gained substantial traction, with the major catalyst being the need for fair and unbiased datasets. Enterprises are gradually realizing the implications of bias within the dataset. Such bias was highlighted in the case of the Apple Card, where women were given lower credit limits than men due to biased training data embedded in the credit disbursal algorithms. Large language models have also been criticized for making negative stereotypes, such as when OpenAI's GPT-3 unintentionally linked objectionable words to certain ethnic groups. These cases stress the need for curating well-balanced training datasets that adequately capture real life scenarios; and are inclusive as well. Other factors helping the market growth include the rise of synthetic data to address privacy concerns and scarcity issues, allowing industries like healthcare and autonomous vehicles to simulate rare scenarios. Other pivotal market trends include the progressively increasing use of multimodal datasets, to power virtual assistants and smart gadgets that require the simultaneous processing of text, images and audio.
By offering, data labeling & annotation software will account for largest market share in 2024 owing to high demand for accurately labelled datasets
The market for data labeling and annotation software is expected to capture a significant share in 2024, driven by the growing need for precisely labeled and context-specific data. A key factor fueling this growth is the increasing demand for detailed annotations that go beyond basic labeling. Companies like Tempus Labs, for instance, rely on meticulously annotated genomic and clinical data to develop precision medicine AI tools, necessitating expert-driven, highly specialized annotations. Additionally, AI-powered annotation automation tools, such as SuperAnnotate, are integrating AI with human annotators in a human-in-the-loop (HITL) system, improving workflow efficiency while maintaining high-quality standards. This approach is gaining traction as organizations seek to minimize manual effort without compromising accuracy. For example, Aptiv is utilizing HITL datasets to train advanced driver-assistance systems (ADAS). Another significant driver is the rising adoption of multimodal data, which requires highly accurate and comprehensively annotated datasets across multiple modalities.
Rising consumption of high-quality datasets to develop domain-specific AI models will push software & technology providers as the fastest growing end user segment during the forecast period
The software and technology providers segment is experiencing the fastest growth in the AI training dataset market, driven by increasing demand for scalable and high-quality dataset creation solutions. These providers, especially cloud hyperscalers like AWS and Google Cloud, are leveraging massive datasets to enhance AI offerings like voice recognition, computer vision, and natural language processing. Microsoft Azure, for instance, has launched several services like Azure Machine Learning that take advantage of large amounts of data to train advanced AI models. Foundation models providers, such as Cohere and Anthropic, are also investing a lot of resources into the procurement of datasets in order to train and custom design LLMs. Furthermore, IT services companies are developing end-to-end data pipelines for their customers, allowing them to scale AI applications with ethically sourced and unbiased training datasets. The segment's robust expansion is also aided by the growing use of industry specific datasets for niche applications like AI in cyber security and supply chain analytics.
North America is set to hold the largest market share in 2024, fueled by a strong regulatory environment and increasing investments in responsible AI deployment
North America has emerged as the largest regional market for AI training dataset, owing to hefty R&D investments being poured into AI. As reported in the 2022 US budget, the federal AI spending of the US government was greater than USD 3.3 billion dollars, which created a demand for quality training datasets. The region's strong focus on advancing large-scale AI models like GPT-4 by OpenAI and DeepMind's AlphaFold also showcases the requirement for multimodal and high-quality training datasets to develop such models. Also, the existence of cloud hyperscalers like AWS, Microsoft Azure, and Google Cloud has sped up the provision of scalable AI solutions, including data annotation and management, as part of their cloud services. In Canada, companies like Element AI (acquired by ServiceNow) are creating sophisticated AI models for sectors like finance and logistics, driving the need for reliable datasets to ensure precision and effectiveness.
Request Sample Pages@ https://www.marketsandmarkets.com/requestsampleNew.asp?id=153819655 [https://www.marketsandmarkets.com/requestsampleNew.asp?id=153819655&utm_source=abnewswire.com&utm_medium=referral&utm_campaign=ai-training-dataset-market]
Unique Features in the AI Training Dataset Market
One of the most distinctive features of the AI training dataset market is the availability of highly diverse datasets, including text, images, audio, video, and sensor data. Multimodal datasets enable AI models to learn from multiple data types simultaneously, improving accuracy and contextual understanding. This diversity supports advanced applications such as computer vision, natural language processing, and speech recognition.
Accurate data labeling is a cornerstone of AI training datasets. The market is characterized by sophisticated annotation techniques such as semantic segmentation, sentiment tagging, object detection, and named entity recognition. Human-in-the-loop systems and AI-assisted labeling tools are widely used to ensure precision, scalability, and efficiency in dataset preparation.
Synthetic data is becoming a key feature in this market, allowing organizations to generate artificial datasets that mimic real-world scenarios. This approach helps overcome challenges like data scarcity, privacy concerns, and bias. Synthetic datasets are especially useful in industries such as autonomous driving, healthcare, and robotics where real data collection can be costly or restricted.
With increasing regulations and data protection laws, the AI training dataset market emphasizes privacy-preserving techniques. Methods such as data anonymization, federated learning, and differential privacy are being integrated to ensure compliance while maintaining data utility. This is particularly important in sensitive sectors like finance and healthcare.
Major Highlights of the AI Training Dataset Market
The AI training dataset market is witnessing significant growth due to the widespread adoption of artificial intelligence across industries. Organizations are increasingly relying on data-driven models for automation, decision-making, and predictive analytics, which is fueling the demand for high-quality training datasets.
A key highlight of the market is the growing need for accurately labeled and structured datasets. As AI models become more complex, the requirement for clean, well-annotated, and context-rich data has intensified, making data quality a critical factor for model performance and reliability.
The market is expanding rapidly across diverse sectors such as healthcare, automotive, retail, BFSI, and manufacturing. Each industry requires specialized datasets tailored to its specific use cases, such as medical imaging, autonomous driving, customer behavior analysis, and fraud detection.
Inquire Before Buying@ https://www.marketsandmarkets.com/Enquiry_Before_BuyingNew.asp?id=153819655 [https://www.marketsandmarkets.com/Enquiry_Before_BuyingNew.asp?id=153819655&utm_source=abnewswire.com&utm_medium=referral&utm_campaign=ai-training-dataset-market]
Top Companies in the AI Training Dataset Market
Some leading players in the AI training dataset market include Google (US), IBM (US), AWS (US), Microsoft (US), NVIDIA (US), Snorkel (US), Gretel (US), Shaip (US), Clickworker (US), Appen (Australia), Nexdata (US), Bitext (US), Aimleap (US), Deep Vision Data (US), Cogito Tech (US), Sama (US), Scale AI (US), Alegion (US), TELUS International (Canada), iMerit (US), Labelbox (US), V7Labs (UK), Defined.ai (US), SuperAnnotate (US), LXT (Canada), Toloka AI (Netherlands), Innodata (US), Kili technology (France), HumanSignal (US), Superb AI (US), Hugging Face (US), CloudFactory (UK), FileMarket (Hong Kong), TagX (UAE), Roboflow (US), Supervise.ly (Estonia), Encord (UK), TransPerfect (US), Keylabs (Israel), and vAIsual (US), Datumo (South Korea), Twine AI (UK), Mostly AI (Austria), FutureBeeAI (India), and Pixta AI (Vietnam).
Appen
Appen is a leading global provider of high-quality AI datasets for AI model training and machine learning (ML) data development. Founded in 1996, the company specializes in curating, annotating, and generating datasets essential for training AI systems across fields like natural language processing (NLP), computer vision, speech recognition, and autonomous technologies. Operating in a niche AI sector, Appen supplies diverse labeled datasets, including LLM datasets, to enterprises worldwide. Its core services encompass data collection, data labeling, and synthetic data generation across multiple formats such as text, images, audio, and video. With a vast workforce spanning 170 countries, Appen ensures culturally diverse datasets covering various languages, dialects, and regional nuances. The company also offers managed services and AI-driven platforms to optimize data annotation processes.
Google, a prominent company in the technology and AI industry, holds a significant position in the AI training dataset market due to its extensive data resources and tools. Using information from platforms like Search, YouTube, and Google Maps, Google creates AI models and offers extensive, public datasets like Google Open Images and Google Speech Commands for tasks involving image recognition and natural language processing. With Google Cloud AI, the company provides pre-trained models and tools for businesses to create AI solutions. The open-source machine learning library, TensorFlow, enables developers to efficiently manipulate data. Dedicated to ethical AI practices, Google prioritizes responsible data usage, privacy safeguards, and bias minimization in its AI training programs. These components are crucial for advancing AI in areas like computer vision and natural language processing, establishing Google as a major player in the AI and ML community, aiding developers of various skill levels in creating sophisticated AI programs.
Scale AI
Scale AI is a leading provider of data labeling and AI infrastructure solutions, enabling organizations to develop and deploy high-quality artificial intelligence models. Founded in 2016, the company specializes in transforming raw data into high-quality training datasets through its scalable data annotation platform, leveraging a combination of automation and human expertise. Scale AI's offerings include labeled datasets for computer vision, natural language processing (NLP), and autonomous systems. Its solutions cater to industries such as autonomous vehicles, defense, robotics, and e-commerce, supporting AI model training with precision-labeled images, videos, and text. The company provides APIs and managed services to streamline data annotation, ensuring accuracy, scalability, and efficiency. With advanced tools Scale AI helps businesses optimize model performance. Backed by major investors, Scale AI plays a pivotal role in accelerating AI adoption by providing the critical data infrastructure necessary for machine learning advancements.
IBM
IBM (US) is a major player in the AI training dataset market, leveraging its expertise in artificial intelligence, cloud computing, and data analytics. Through its Watson AI platform and various data annotation and curation services, IBM provides high-quality datasets for machine learning model training across industries such as healthcare, finance, and autonomous systems. The company also integrates ethical AI principles, focusing on data privacy, bias mitigation, and compliance with global regulations. Its AI training data solutions support enterprises in building robust, scalable AI models with improved accuracy and fairness.
Media Contact
Company Name: MarketsandMarkets Trademark Research Private Ltd.
Contact Person: Mr. Rohan Salgarkar
Email:Send Email [https://www.abnewswire.com/email_contact_us.php?pr=ai-training-dataset-market-futuristic-opportunity-high-cagr-value-emerging-demands-and-future-outlook]
Phone: 18886006441
Address:1615 South Congress Ave. Suite 103, Delray Beach, FL 33445
City: Florida
State: Florida
Country: United States
Website: https://www.marketsandmarkets.com/Market-Reports/ai-training-dataset-market-153819655.html
Legal Disclaimer: Information contained on this page is provided by an independent third-party content provider. ABNewswire makes no warranties or responsibility or liability for the accuracy, content, images, videos, licenses, completeness, legality, or reliability of the information contained in this article. If you are affiliated with this article or have any complaints or copyright issues related to this article and would like it to be removed, please contact retract@swscontact.com
This release was published on openPR.
Permanent link to this press release:
Copy
Please set a link in the press area of your homepage to this press release on openPR. openPR disclaims liability for any content contained in this release.
You can edit or delete your press release AI Training Dataset Market Futuristic Opportunity, High CAGR Value, Emerging Demands and Future Outlook here
News-ID: 4436556 • Views: …
More Releases from ABNewswire

Probiotic Yeast Market Size, Share, Industry Growth, Market Trends, and Forecast …
Probiotic Yeast Market by Product Type (Functional Food & Beverages, Dietary Supplements, Animal Feed), Yeast Strain Type (Saccharomyces boulardii, Saccharomyces cerevisiae, Others), End User, Distribution Channel, and Region - Global Forecast to 2030
The t [https://www.marketsandmarkets.com/Market-Reports/probiotic-yeast-market-225076341.html] is projected to grow from USD 10.21 billion in 2025 and to reach USD 16.23 billion by 2030, at a Compound Annual Growth Rate (CAGR) of 9.7% during the forecast period. The probiotic yeast market…
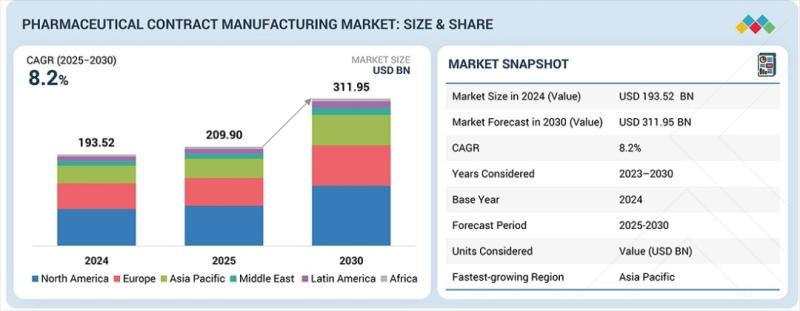
Pharmaceutical Contract Manufacturing Market to Reach USD 311.95 Billion by 2030
Rising Demand for Biologics and GLP-1 Capacity Expansion Drive an 8.2% CAGR as Pharmaceutical Giants Increasingly Pivot Toward Strategic CDMO Partnerships
The global pharmaceutical contract manufacturing market [https://www.marketsandmarkets.com/Market-Reports/pharmaceutical-contract-manufacturing-market-201524381.html?utm_source=abnewswire.com&utm_medium=referral&utm_campaign=Paidpr-k] is entering a phase of unprecedented growth, projected to surge from USD 209.90 billion in 2025 to USD 311.95 billion by 2030. This expansion, representing a compound annual growth rate (CAGR) of 8.2%, is fundamentally reshaped by a "perfect storm" of industry shifts.…
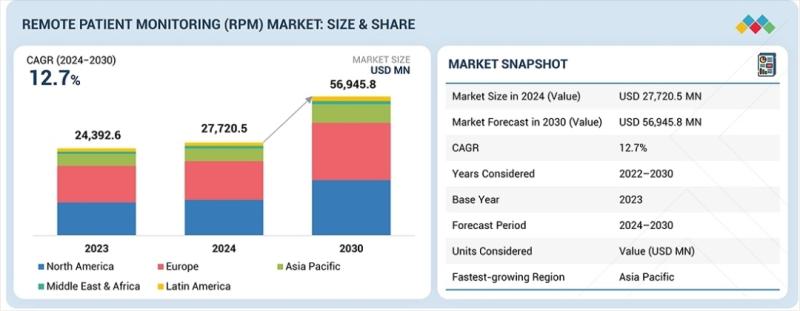
Remote Patient Monitoring Market to Reach USD 56.945 Billion by 2030
Digital Transformation and Rising Chronic Disease Prevalence Fuel 12.7% CAGR in Global Remote Healthcare Solutions
The global Remote Patient Monitoring (RPM) Market [https://www.marketsandmarkets.com/Market-Reports/remote-patient-monitoring-market-77155492.html?utm_source=abnewswire.com&utm_medium=referral&utm_campaign=Paidpr-k] is currently undergoing a massive structural shift, projected to grow from USD 27,720.5 million in 2024 to a staggering USD 56,945.8 million by 2030. This trajectory represents a compound annual growth rate (CAGR) of 12.7% over the forecast period. The primary catalysts driving this expansion include the rapid…

Pharmaceutical & Cosmetics Anti-counterfeit Packaging Market In-depth Insights, …
The Pharma & Cosmetic Anti-Counterfeit Packaging Market is witnessing strong demand driven by rising counterfeit risks, stringent regulations, and growing consumer awareness. Advanced technologies such as serialization, QR codes, and smart packaging are enhancing product security, ensuring brand protection, and supporting market growth globally.
The Pharmaceutical & Cosmetics Anti-counterfeit Packaging Market is projected to reach USD 195.0 billion by 2030 from USD 96.3 billion in 2025, at a CAGR of 15.17%…
More Releases for Data
Data Catalog Market: Serving Data Consumers
Data Catalog Market size was valued at US$ 801.10 Mn. in 2022 and the total revenue is expected to grow at a CAGR of 23.2% from 2023 to 2029, reaching nearly US$ 3451.16 Mn.
Data Catalog Market Report Scope and Research Methodology
The Data Catalog Market is poised to reach a valuation of US$ 3451.16 million by 2029. A data catalog serves as an organized inventory of an organization's data assets, leveraging…
Big Data Security: Increasing Data Volume and Data Velocity
Big data security is a term used to describe the security of data that is too large or complex to be managed using traditional security methods. Big data security is a growing concern for organizations as the amount of data generated continues to increase. There are a number of challenges associated with securing big data, including the need to store and process data in a secure manner, the need to…
HOW TO TRANSFORM BIG DATA TO SMART DATA USING DATA ENGINEERING?
We are at the cross-roads of a universe that is composed of actors, entities and use-cases; along with the associated data relationships across zillions of business scenarios. Organizations must derive the most out of data, and modern AI platforms can help businesses in this direction. These help ideally turn Big Data into plug-and-play pieces of information that are being widely known as Smart Data.
Specialized components backed up by AI and…
Test Data Management (TDM) Market - test data profiling, test data planning, tes …
The report categorizes the global Test Data Management (TDM) market by top players/brands, region, type, end user, market status, competition landscape, market share, growth rate, future trends, market drivers, opportunities and challenges, sales channels and distributors.
This report studies the global market size of Test Data Management (TDM) in key regions like North America, Europe, Asia Pacific, Central & South America and Middle East & Africa, focuses on the consumption…
Data Prep Market Report 2018: Segmentation by Platform (Self-Service Data Prep, …
Global Data Prep market research report provides company profile for Alteryx, Inc. (U.S.), Informatica (U.S.), International Business Corporation (U.S.), TIBCO Software, Inc. (U.S.), Microsoft Corporation (U.S.), SAS Institute (U.S.), Datawatch Corporation (U.S.), Tableau Software, Inc. (U.S.) and Others.
This market study includes data about consumer perspective, comprehensive analysis, statistics, market share, company performances (Stocks), historical analysis 2012 to 2017, market forecast 2018 to 2025 in terms of volume, revenue, YOY…
Long Term Data Retention Solutions Market - The Increasing Demand For Big Data W …
Data retention is a technique to store the database of the organization for the future. An organization may retain data for several different reasons. One of the reasons is to act in accordance with state and federal regulations, i.e. information that may be considered old or irrelevant for internal use may need to be retained to comply with the laws of a particular jurisdiction or industry. Another reason is to…
